


阿里妹导读
文章旨在为AI开发者提供可复用的技术路径与经验借鉴,帮助避免常见“踩坑”场景,从而构建更加智能、可靠的对话系统。
概述
我们在构建AI智能体的过程中,意图识别和槽位抽取是自然语言理解(NLU)的两个关键部分,会直接影响智能体的交互质量和用户体验。
意图识别(Intent Detection)的核心作用在于准确判断用户的语义目的。系统能将用户输入映射到预定义的意图类别(如"查询天气"、"预订餐厅"),这一步骤决定了后续业务流程的正确走向。若意图识别错误,整个对话流程就会偏离用户真实需求。
槽位抽取(Slot Filling)则负责结构化关键信息。从语句中提取出时间、地点、数量等实体参数。这些槽位值构成了执行具体操作的必备参数。例如在订餐场景中,必须准确提取"菜品名称"、"送餐地址"等核心槽位。
二者共同构成语义解析的完整链路,直接影响对话状态的准确性。
我们团队在过去一年中,负责开发了十余个智能体,进行了上百次迭代开发任务,通过不断掉坑和爬坑的过程,逐步探索出一套完善的方法论,显著提升了意图识别和槽位抽取的准确性,并附上了详实的数据对比,以供大家参考。
初级方案A(提示词工程)
这是我们最初采用的方案,也是当前多数智能体所采用的常见方法。在单一模型节点中,通过精心设计的提示词优化,实现意图识别与槽位抽取任务。
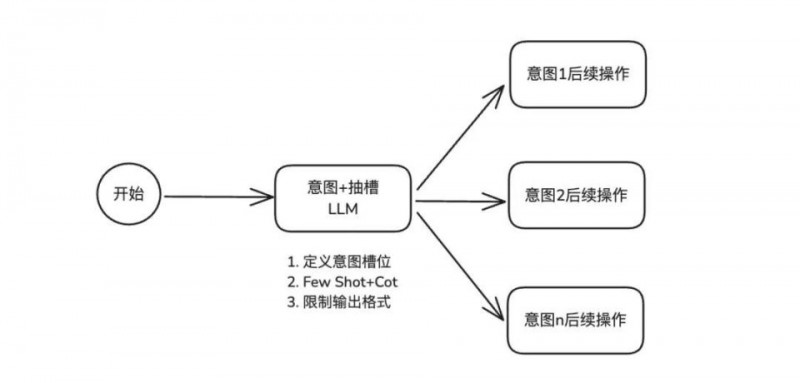
提示词工程进行意图识别和槽位提取主要涵盖三个关键模块。
首先是 “定义意图槽位”,此处需精准框定智能体需识别的各类意图范畴,以及对应槽位的名称、数据类型与取值范围,如同为智能体打造详尽的任务字典。
其次是 “每个意图和槽位的 Few-Shot + CoT”,为每个意图搭配 Few-Shot 示例,就像给智能体提供典型范例,使其领会如何从输入文本精准抽取槽位信息;同时融入 CoT,引导智能体逐步剖析用户输入,剖析语义结构,定位关键信息。
最后是 “输出格式”,明确规定智能体以结构化格式(如 JSON、XML 等标准数据格式)输出识别结果,确保后续系统能便捷解析利用,提升交互流程的连贯性与效率。
提示词关键部分
(1)定义意图槽位
方案特性
优点
此方法的优点在于简单高效。通过提示词设计,无需添加复杂的额外算法或模型架构,就可使 AI 智能体快速具备意图识别和槽位抽取能力。在意图数量较少的情况下,这种方法能以较低成本实现较好效果,能满足用户需求。tion-ignore="true" data-cangjie-void="true" style="box-sizing:inherit;display:inline-block;max-width:100%;text-indent:initial">
缺点
当意图数量增多时,为每个意图定义槽位以及编写相应数量的 Few - Shot + CoT 内容,会使提示词长度大幅膨胀。会给模型带来巨大的处理负担,使模型难以准确地捕捉和理解其中的关键内容,容易出现混淆和错误的关联,进而影响其对意图和槽位的准确识别和抽取。
适用场景
该方案更加适用于那些意图分支相对较少,且业务场景对识别准确性具有一定容错空间的场景。
中级方案B(意图和抽槽节点分离)
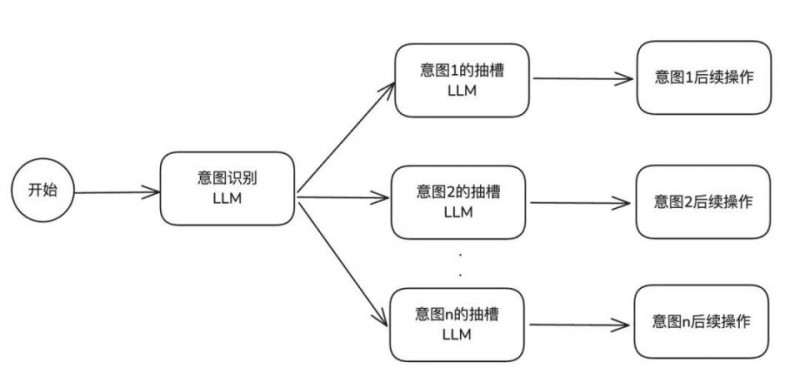
方案特性
优点tion-ignore="true" data-cangjie-void="true" style="box-sizing:inherit;display:inline-block;max-width:100%;text-indent:initial">
从系统结构层面来看,一个意图关联一个抽槽节点的配置方式,使得系统架构在逻辑上更为清晰简洁,极大地降低了结构的复杂程度,为后续的系统维护与功能迭代提供了极大的便利。这种对应关系确保了每个抽槽节点的职责单一且明确,仅专注于对应意图所关联信息的抽取任务,避免了多意图抽槽任务交叉可能带来的干扰与冲突。
同时,这种设计允许 prompt 长度支持更大,因为模型在对单意图进行语义解析时,不会受到其他无关意图信息的干扰,能够更加专注于对复杂文本语境中的关键要素进行捕捉与解读。
这种解耦架构在面对复杂多变的业务场景和不断变化的用户需求时,展现出了较强的适应能力。当需要新增或修改某个意图及其对应的抽槽规则时,只需针对相应的抽槽节点进行调整,而无需对整个系统架构进行大规模的重构,大大提高了系统的可维护性和可扩展性,确保了智能体能够快速响应业务变化,持续保持高效的语义理解与信息抽取能力,为各种应用场景提供精准、可靠的服务支持。
缺点
这种架构下,每个意图和抽槽都是独立的节点,这意味着在实际运行中,系统需要分别调用AI来处理意图识别和抽槽任务,这无疑增加了系统的调用次数。每一次调用都需要消耗一定的计算资源和时间,这就导致了整体系统的延迟增大。
这种延迟对于一些对实时性要求较高的应用场景来说,可能会成为一个明显的问题,影响用户体验。
适用场景
该方案更加适用于那些意图分支较为复杂且繁多,同时对延迟敏感度较低的业务场景,在这些场景下,其优势能够得到更充分发挥。
进阶方案C(意图识别优化:前置意图Rag召回)
进阶背景
按照前面的方案,我们研发并上线了一些 AI 智能体。客户用下来之后,反馈智能体不够智能,主要问题集中在智能体不能准确识别出客户想要表达的意思。
通过我们和业主、客户多次沟通交流,发现客户真正想要的是智能体能够理解准确各种各样、形式各异但意思相近的问题(比如方言类、反问语气、情绪化语气等),这就要求 LLM 节点得有很强的泛化和识别能力。
采用参数大、满血的大语言模型会比参数小的模型泛化能力强,固然准确性会有所提升。但这种大模型节点存在一些局限性,无法通过人工方式进行有效控制,难以快速修复 Bad Case,且满血模型的使用成本和响应时长也会升高。
所以,如何将特异的问题问题对应到准确的意图上,是阶段性的重点任务。经过研究,最后采用了LLM提前泛化意图的方法,再通过 RAG 召回的方式,来解决之前那些智能体意图识别不准确的问题。
方案说明
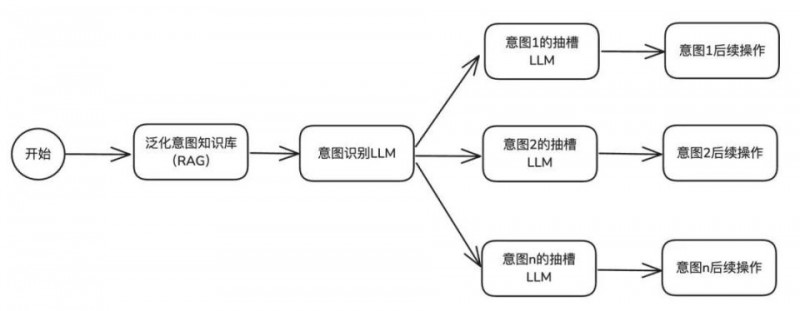
在前期方案基础上,我们加入了 RAG 召回能力,专门解决垂类领域和特异性表达Query的意图识别。在知识库里上传大量意图分类知识,用户提问时,先用 RAG 召回找到相似的 query 和意图对应关系,作为案例提交给 LLM 处理,让大模型更好地理解垂类或个性化分类判定逻辑。
这个方案对模型推理和泛化能力要求不高,建议选用性价比高的 qwen-turbo、qwen-plus 等模型。
意图知识库工作
首先,我们要根据具体的垂类行业来确定意图分类,以及对每个意图进行精准的描述。
接下来,通过人工构造和收集线上的 Query 来获取意图语料。由于下一步要进行模型泛化,所以这里的种子语料数量最好能多一些,尽量达到 30~50 个左右。
(2)意图数据泛化
利用 LLM 对种子语料生成一批同义句,运用基模理解强化机制进行同义替换,实现全面覆盖。
每个意图都需要包含多种句式变体,涵盖口语化表达、地域化表达以及反问句转化训练等内容。例如,将「难道没有坐车的码吗?」这样的反问句,准确映射至「打卡乘车码」这一意图。
泛化意图query代码示例
示例:泛化后【打开乘车码】意图的query列表
打开乘车码意图(泛化后的query)
方案特性
优点
通过将识别 Query 意图的工作,从 LLM 实时泛化识别过程转变为预泛化,从而掌控了项目整体的意图识别泛化能力水平,使得意图识别的准确性得以保持在较高水位。
在面对线上出现的未被覆盖的 query 意图识别场景时,能够迅速做出响应并加以修复,仅需通过添加知识库条目的方式,就能快速实现对该场景的覆盖,无需进行修改提示词以及调优等相对复杂繁琐的操作,大大提高了问题解决的效率。
缺点
方案需要对意图和问题数据开展泛化预处理工作,这在一定程度上增加了研发成本;
虽然在单轮会话中,意图识别能力表现良好,但在涉及多轮对话,需要综合多轮信息来综合判断意图的场景下,效果就显得不够理想了。
高阶方案D
(合并意图抽槽节点 + 升级前置Rag召回能力)
现实场景中,业务需求往往远比预想的更为复杂。例如,如何依据多轮对话内容准确判断意图和槽位,以及如何合理切分不同意图的对话内容,避免其在模型识别过程中相互干扰等问题,都极具挑战性。
面对既要低延迟又要高准确性的意图识别和槽位填充任务,这对我们的技术方案提出了全新的挑战。基于这一挑战,我们设计并落地了此方案。
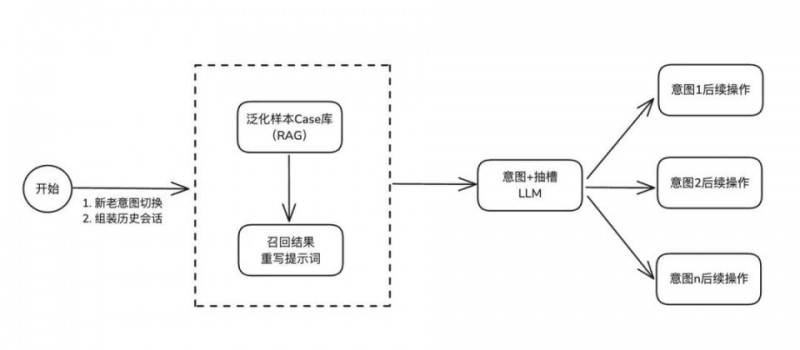
方案关键部分
组合出来的结果示例
为此,我们在意图知识库中特别设置了一个【处理】字段,其值分别为【意图路由】和【直接回答】。对于那些无需大模型处理的意图,我们将【处理】字段设置为【直接回答】。在进行 query 召回后,我们会进行判断,若该意图被标记为【直接回答】,则直接将 RAG 中预设的回答文案迅速返回给客户。
通过这种优化处理,我们不仅提高了智能体的响应效率,还确保了用户能够及时获得准确、简洁的答案,进一步提升了项目整体运行效果。
在多轮对话场景下,意图解析和抽槽过程易受干扰,主要体现在以下两个方面:
话题迁移与意图混淆:多轮对话中话题可能切换或延伸,用户表达可能涉及旧意图或新意图。模型若无法准确追踪话题变化,容易混淆不同轮次的意图,导致意图解析不准确。
槽位更新与整合难题:多轮对话中,槽位信息可能在不同轮次中补充或更正。模型需要整合多轮信息以确定槽位值,若无法有效处理,会导致槽位抽取不准确,影响对话连贯性。
为了解决多轮对话中意图解析和槽位抽取易受干扰的问题,我们的方案是:
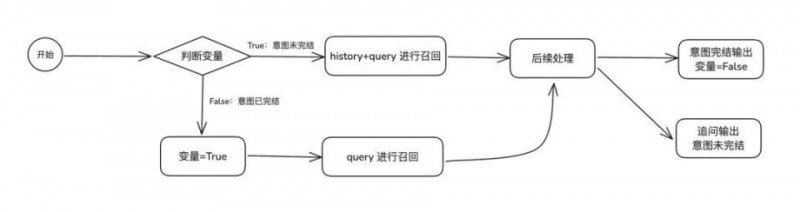
意图切断策略:当意图A的执行流程完全结束后,若新的会话意图B进入对话系统,应根据既定策略清空意图A的历史会话记录。这样可以避免意图A的信息对意图B的召回和后续处理过程产生干扰,从而提升意图解析和槽位抽取的准确性和独立性。
方案特性
优点
方案C在确保节点延迟稳定的基础上,显著提升了在复杂意图分支场景下的准确性。此外,针对线上意图抽槽过程中出现的Bad Case,我们可以通过维护知识库RAG进行快速修复,无需对智能体进行改动或重新发布。
缺点
需要对数据进行泛化预处理,并对【历史提问】、【最新提问】、【思考过程】、【意图】、【槽位】等字段进行内容准备和标注,工作量相较于仅进行意图分类的泛化要大得多。
因此,建议在前期泛化时,每个意图仅提交 5-10 个 Case,随着项目的推进,逐步对齐并控制成本。
方案横向对比数据
数据测试样本:采用已上线的出行行业智能体项目(上海地铁智能体),项目有13个预设意图分支,测评集数量443条用例。
写在最后
在过去一年的智能体研发项目中,我们团队历经诸多挑战,不断探索、实践并逐步优化,最终产出当前的技术方案,是我们在实际项目推进过程中,逐步积累的实践成果。
四种方案在不同场景下皆有用武之地,通过对项目的评估,客户的诉求来选择对应的方案,才是最佳的实践效果。
Kimi K2,开源万亿参数大模型
先进的混合专家(MoE)语言模型,在前沿知识、推理和编码任务中性能卓越,并优化了工具调用能力。本方案支持云上调用 API 与部署方案,无需编码,最快 5 分钟即可完成,成本最低 0 元。


